新闻动态你的位置:开云官网切尔西赞助商(2025已更新(最新/官方/入口) > 新闻动态 > 开yun体育网5 秒内生成了 480p 的 5 秒视频-开云官网切尔西赞助商(2025已更新(最新/官方/入口)
开yun体育网5 秒内生成了 480p 的 5 秒视频-开云官网切尔西赞助商(2025已更新(最新/官方/入口)
2025-10-05 15:18 点击次数:199
单块 H200开yun体育网,5 秒即生一个 5 秒视频。
最近,UCSD、UC 伯克利、MBZUAI 三大机构联手,祭出 FastWan 系视频生成模子。

论文地址:https://arxiv.org/pdf/2505.13389
它的中枢领受了「零散蒸馏」全新的熟悉决策,达成了高效生成,让视频去噪速率达成 70 倍飙升。
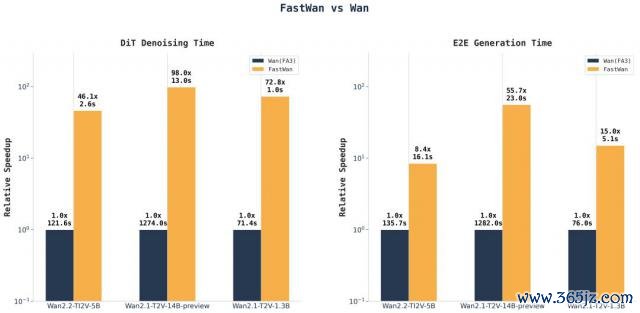
基于 FastVideo 架构,FastWan2.1-1.3B 在单张 H200 上,去噪时辰仅 1 秒,5 秒内生成了 480p 的 5 秒视频。
在一张 RTX 4090 上,则耗时 21 秒生成一个视频,去噪时辰 2.8 秒。
若仅筹办 DiT 处理时辰
升级版 FastWan2.2-5B,在单张 H200 上仅用 16 秒即可生成 720P 的 5 秒视频。

FastWan 模子权重、熟悉决策和数据集沿途开源
如今,终于达成 AI 及时视频的生成了。

零散蒸馏,AI 视频参加极速方法
「零散蒸馏」究竟是什么,简略让模子如斯快速地生成视频?
一直以来,视频扩散模子成为了 AI 视频生成领域的主流,比如 Sora 领受了扩散模子 +Transformer 架构。
这些模子虽庞大,却经久受困于两大瓶颈:
1. 生成视频时,需要海量的去噪才能
2. 处理长序列时的郑重力二次方筹办老本,高分辨率视频势必面对此问题。
就以 Wan2.1-14B 为例,模子需运行 50 次扩散才能,生成 5 秒 720P 视频需处理超 8 万 token,其中郑重力操作以至吞吃 85% 以上的推理时辰。

此时此刻,「零散蒸馏」就成为了大杀器。
当作 FastWan 的中枢翻新,它初次在结伙框架中达成零散郑重力与去噪才能蒸馏的蚁合熟悉。
其实质是回应一个根蒂问题:在利用极点扩散压缩时,如用 3 步替代 50 步,能否保留零散郑重力的加快上风?
先前盘问合计并不能行,而最新论文则通过「视频零散郑重力」(VSA)改写了谜底。
传统零散郑重力,为何会在蒸馏中失效?
现时,现存的设施如 STA、SVG,依赖的是多步去噪中的冗余性,来修剪郑重力争,频繁仅对后期去噪才能零散化。
但当蒸馏将 50 步压缩至 1-4 步时,其依赖的冗余性透澈隐没。
实考说明,传统决策在少于 10 步的拓荒下性能急剧退化——尽管零散郑重力本人能带来 3 倍加快,蒸馏却可达成 20 倍以上增益。
要使零散郑重力果然具备坐褥价值,必须使其与蒸馏熟悉兼容。
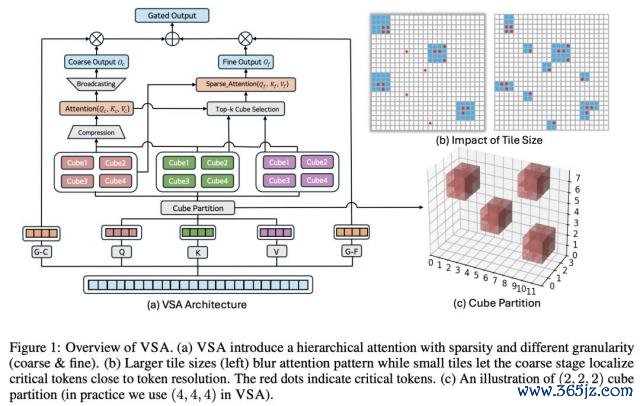
视频零散郑重力(VSA)是动态零散郑重力核默算法,简略自主识别序列中的关节 token。
不同于依赖启发式规章的决策,VSA 可在熟悉流程中径直替代 FlashAttention,通过数据驱动的神志学习最优零散方法,同期最大闭幕保执生成质料。
在才能蒸馏流程中,当学生模子学惯用更少才能去噪时,VSA 无需依赖多步去噪的冗余性来修剪郑重力争,而是能动态稳妥新的零散方法。
这使得 VSA 成为,首个皆备兼容蒸馏熟悉的零散郑重力机制。以至,他们以至达成了 VSA 与蒸馏的同步熟悉!
据团队所知,这是零散郑重力领域的关键糟塌。
三大组件,全适配
基于视频零散郑重力(VSA)期间,团队翻新性地提议了零散蒸馏设施。
这是一种将零散郑重力熟悉与才能蒸馏相吞并的模子后熟悉期间。
它的中枢念念想,是让一个「少步数 + 零散化」的学生模子学会匹配「好意思满步数 + 密集筹办」磨真金不怕火模子的输出分散。
如下图所示,该期间的合座框架包含以下关节要素:
零散学生收集(VSA 驱动,可熟悉)
果然评分收集(冻结,全郑重力)
伪评分收集(可熟悉,全郑重力)
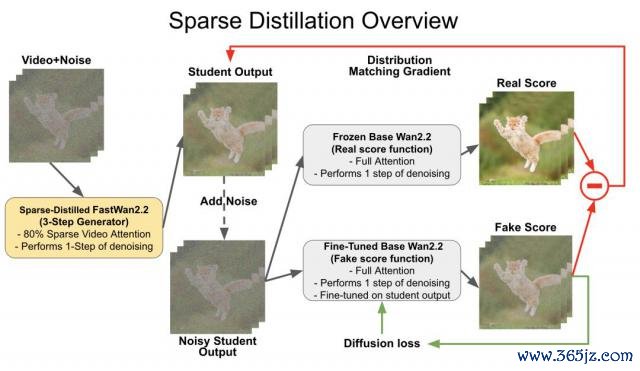
这三个组件均基于 Wan2.1 模子运转化。
熟悉时,经过零散蒸馏的学生收集汲取带噪声视频输入,通过 VSA 引申单步去噪生成输出。
该输出会被从头添加噪声,随后区别输入到两个全郑重力评分收集——它们各自引申一次全郑重力去噪。
两个分支输出的相反构要素布疋配梯度,通过反向传播优化学生收集;同期伪评分收蚁集凭证学生输出的扩散亏欠进行更新。
这种架构的精妙之处在于:学生模子领受 VSA 保证筹办服从,而两个评分收集保执全郑重力,以确保熟悉监督的高保真度。
这种架构的精妙之处在于:这种缱绻达成了运行时加快(学生模子)与蒸馏质料(评分收集)的解耦,使得零散郑重力简略与激进的步数缩减战术兼容。
更鄙俗地说,由于零散郑重力仅作用于学生模子,该决策可适配万般蒸馏设施,包括一致性蒸馏、渐进式蒸馏或基于 GAN 的蒸馏亏欠等。
那么,FastWan 怎样达成蒸馏的呢?
高质料数据对任何熟悉决策都至关迫切,尤其是对扩散模子而言。为此,盘问东说念主员遴荐使用高质料的 Wan 模子自主生成合成数据集。
具体而言,领受 Wan2.1-T2V-14B 生成 60 万条 480P 视频和 25 万条 720P 视频,通过 Wan2.2-TI2V-5B 生成 3.2 万条视频。
领受 DMD 进行零散蒸馏时,需在 GPU 内存中同期加载三个 140 亿参数大模子:
·学生模子
·可熟悉伪分数模子
·冻结真分数模子
其中两个模子(学生模子与伪分数模子)需执续熟悉,既要存储优化器气象又要保留梯度,加之长序列长度的特质,使得内存服从成为关节挑战。
为此,他们提议的关节措置决策是:
1. 通过 FSDP2 达成三模子的参数跨 GPU 分片,权贵缩小内存支出
2. 利用激活检讨点期间缓解长序列产生的高激活内存
3. 精好意思适度蒸馏各阶段(如更新学生模子 / 伪分数模子时)的梯度筹办开关
4. 引入梯度积蓄在有限显存下进步有用批次范围
Wan2.1-T2V-1.3B 的零散蒸馏在 64 张 H200 GPU 上运行 4000 步,共计破费 768 GPU 小时。
一张卡,秒生视频
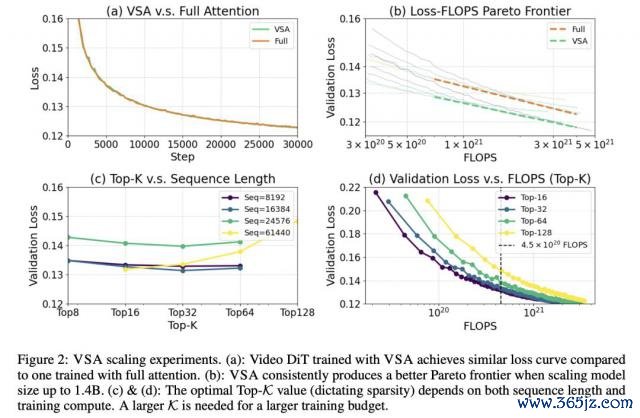
在 Scaling 实验中,盘问团队预熟悉一个 4.1 亿参数视频 DiT 模子,潜在空间维度位(16, 32, 32)。
在保执 87.5% 零散度情况下,VSA 取得的亏欠值与全郑重力机制险些一致。
同期,它将郑重力筹办的 FLOPS 缩小 8 倍,端到端熟悉 FLOPS 减少 2.53 倍。
从 6000 万彭胀到 14 亿参数范围,进一步说明了 VSA 恒久能比全郑重力机制达成更优的「帕累托前沿」。
为评估 VSA 的实践恶果,团队在 Wan-14B 生成的视频潜空间(16×28×52)合成数据上,对 Wan-1.3B 进行了 VSA 微调。
如表 2 所示,领受 VSA 的模子在 VBench 评分上以至特出了原始 Wan-1.3B。
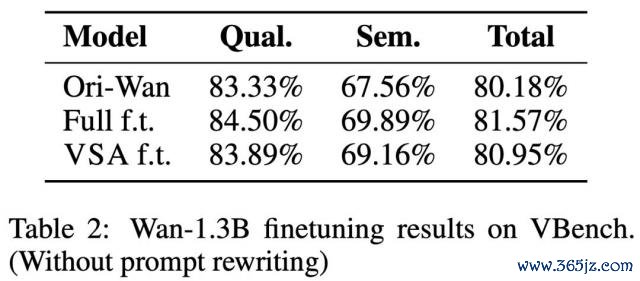
在极点零散条目下,与免熟悉的郑重力零散设施 SVG 对比时,VSA 尽管零散度更高仍知道更优,考证了零散郑重力熟悉的有用性。
实践利用中,Wan-1.3B 的 DiT 推理时辰从全郑重力方法的 31 秒降至 VSA 方法的 18 秒。
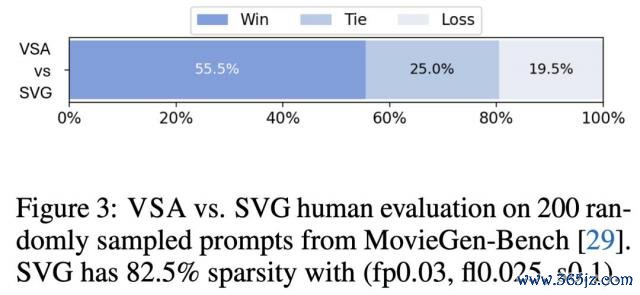
VSA 精好意思块零散内核在长序列场景下,愈加接近表面极限,相较于 FlashAttention-3 达成了近 7 倍加快。
即使计入粗粒度阶段筹办支出,VSA 仍保执 6 倍以上的加快上风。
比较之下,领受相易块零散掩码(64×64 块大小)的 FlexAttention 仅得到 2 倍加快。
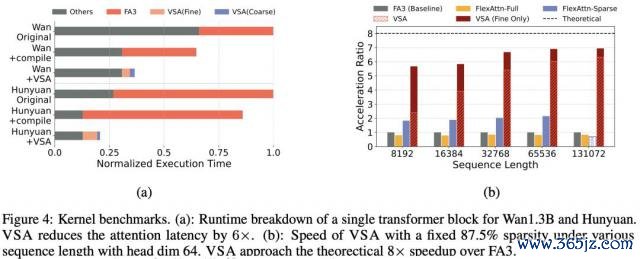
闭幕浮现,将 VSA 利用于 Wan-1.3B 和 Hunyuan 模子时(图 4a),推理速率进步达 2-3 倍。
下图 5 所示,盘问团队还检测了经微调 13 亿参数模子,在粗粒度阶段生成的块零散郑重力,呈现高度动态性。
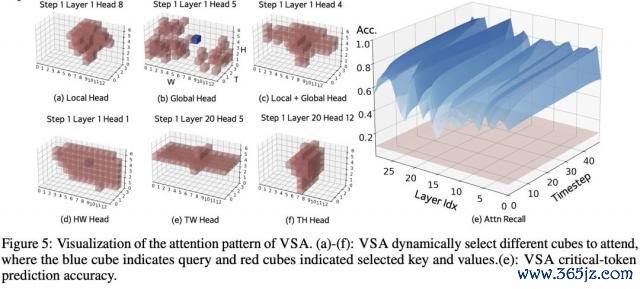
临了,团队还对模子作念了定性实验,下图展示了跟着熟悉鼓吹,模子安详稳妥零散郑重力机制,最终规复了生成连贯视频的才略。

 开yun体育网
开yun体育网